Key Takeaways
A credible headless eCommerce development process moves through five stages: risk-led discovery, architecture and data design, phased delivery, hard testing of checkout and integrations, then planned cutover and handoff. Most projects fail not because the front end looked bad, but because discovery stayed shallow, integrations were guessed, and launch planning started after technical debt was already baked in.
- Discovery must expose risk, not just collect requirements. You need clear answers on who owns product data, customer data, pricing rules, promotions, content publishing, and exception handling before build starts.
- Architecture and data design settle before build starts. Platform fit is not architecture fit. Variants, bundles, localisation, merchandising rules, subscriptions, trade pricing, and customer-specific catalogues all change how the build should be structured.
- Checkout, integrations, and load are where polished demos fall apart. Stock arrives late from ERP, account pricing applies to the wrong customer group, or a payment delay leaves the basket in limbo. That is not a front-end issue, it is a process issue left too late.
- Launch, cutover, and handoff should be planned long before go-live. You need to know how content freeze will work, when routing or sync changes happen, who watches monitoring, what support cover exists, and what defect threshold triggers rollback.
The selection test is simple: can the supplier show how they move from discovery to cutover without guessing the hard parts, hiding client effort, or hand-waving edge cases?
Most headless eCommerce projects go wrong not because of technical failure, but because the process was skipped. Discovery stayed shallow. Integrations were guessed. Product data was treated as admin detail. Launch planning started after technical debt was already baked in. That is usually the point at which a polished proposal stops feeling reassuring.
The short answer: A credible headless ecommerce development process runs through five stages – risk-led discovery, architecture and data design, phased delivery, hard testing of checkout and integrations, then planned cutover and handoff. Each stage has defined outputs. If a supplier cannot show those outputs, the process is not real.
If you are comparing agencies for developing your eCommerce website in London, or shaping a brief before scoping starts, use this as a benchmark.
Discovery should expose risk, not just collect requirements
Good discovery is not a workshop where everyone repeats the brief in cleaner slides. Its job is to find what is missing, what conflicts, and what will break when APIs, stock rules, pricing logic, and content workflows hit real trading conditions.
What weak suppliers skip: ownership, constraints, and ugly operational detail. You need clear answers on who owns product data, customer data, pricing rules, promotions, content publishing, and exception handling. If nobody owns those decisions, the build is not ready.
A common scenario is a team asking for a faster storefront and better UX, while the real risk sits in ERP sync, account-specific pricing, and approval-heavy content workflows. The visible brief says new front end. The real project is an integration and governance problem wearing a design badge.
By the end of discovery, you should have a prioritised scope, dependency map, risk log, and a brief that is ready for decisions – not a revised summary of what you already told them. If you want a deeper view of what a proper eCommerce discovery workshop should produce before build starts, that is often where weak process shows itself first.
Architecture and data design must be settled before build starts
This is where rushed projects start creating future cost. Suppliers often move straight to platform names – React, Next.js, Shopify, WooCommerce, Magento – before answering the harder question: where should business logic live, and how will the data behave under real use?
Platform fit is not architecture fit. Having managed headless builds across Shopify, Magento, and WooCommerce, my consistent observation is that these platforms stop being interchangeable the moment B2B pricing, account permissions, catalogue complexity, and operational overhead are mapped properly. A platform that looks clean in a demo can become expensive to run once the edge cases arrive. Headless Shopify, headless WooCommerce, and headless commerce API design each carry different long-term maintenance cost – and that cost is rarely visible in a proposal.
Data shape decides more than most buyers expect
Push on the product data model early. Variants, bundles, localisation, merchandising rules, subscriptions, trade pricing, and customer-specific catalogues all change how the build should be structured. If a supplier says they will work that out during development, treat that as a warning, not flexibility.
This stage should end with architecture direction, data assumptions, integration approach, and known edge cases written down. If those decisions are still vague, front-end and API work will drift apart – and the cost of correcting that drift lands in your budget, not theirs.

Not sure if your headless ecommerce brief is ready for scoping?
We run focused discovery sessions that expose integration risk, data ownership gaps, and hidden operational constraints before build starts. You get a clear view of what needs settling, what can wait, and where supplier proposals usually hide future cost.
Quick diagnostic call, no obligation, just clearer next steps.
What a serious delivery plan actually looks like
A serious delivery plan should feel controlled from the start. It should not rely on everything somehow coming together near launch. You need to know what happens in each phase, what your team must review, and where approvals typically slow things down.
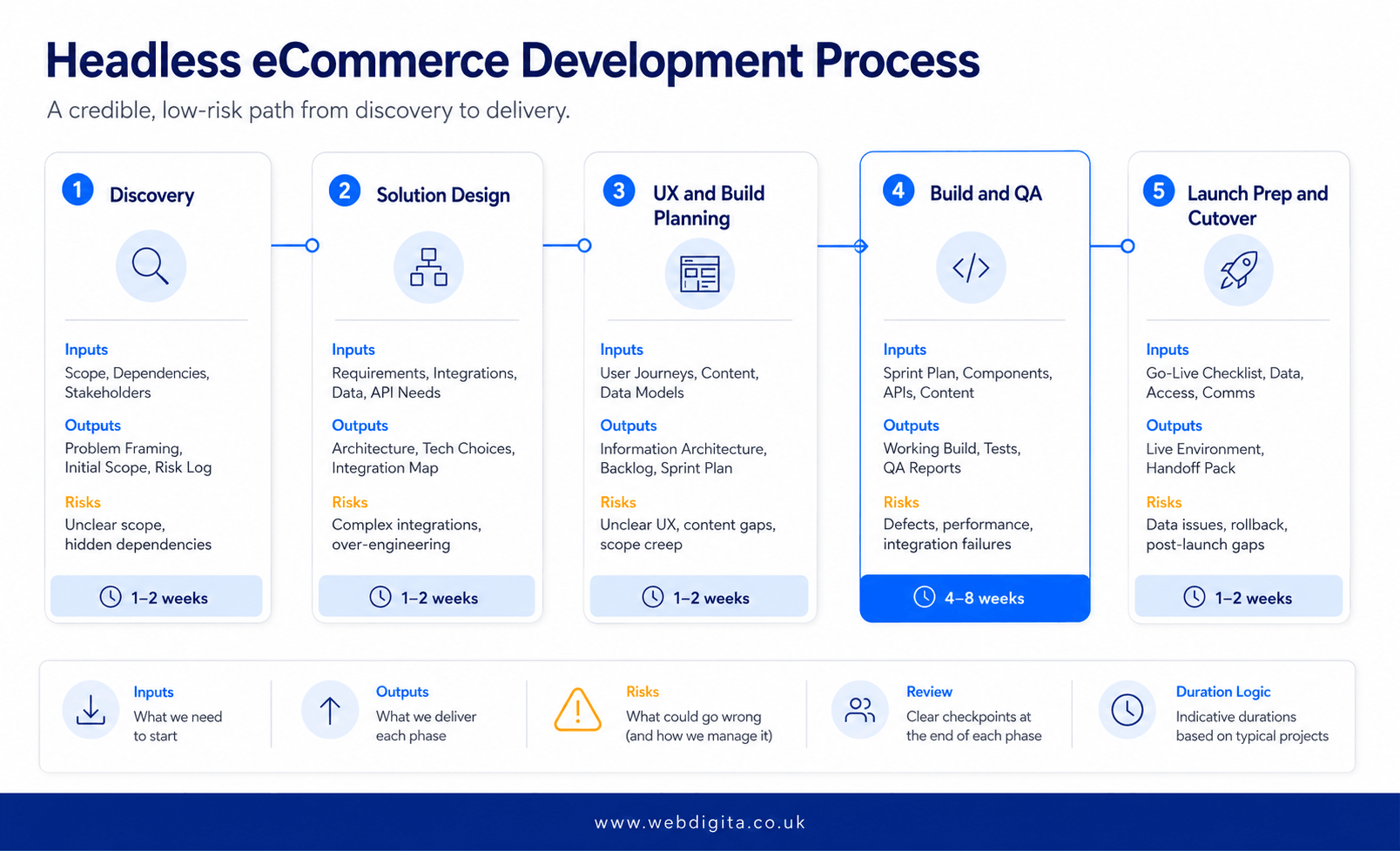
If a agency cannot explain outputs, dependencies, and client effort per phase, ask them to slow down. That is exactly where a eCommerce project discovery workshop adds the most value.
Discovery: Inputs are goals, pain points, system landscape, and stakeholder constraints. Required outputs: prioritised scope, risk log, dependency map, and success criteria. Duration grows with system complexity and stakeholder misalignment – not with project ambition.
Solution design: Inputs are approved scope and system requirements. Required outputs: architecture direction, data model assumptions, integration plan, and acceptance logic. This phase must close the decisions that prevent build drift. If it does not, the build inherits the ambiguity.
UX and build planning: Inputs are architecture choices and user journey priorities. Required outputs: component plans, content requirements, API contracts, and sprint sequencing. Your internal team will typically need to review journeys, content gaps, and business rules here – underestimate that effort at your own risk.
Build and QA: Inputs are signed-off designs, API definitions, and test cases. Required outputs: working features, integration validation, defect logs, and acceptance sign-off. Client-side review effort in this phase is consistently underestimated. Build it into your resource plan.
Launch prep and cutover: Inputs are the release candidate, migration plan, and support cover. Required outputs: launch criteria, rollback plan, monitoring ownership, and documented handoff. The timeline varies – the logic should always be visible before you agree a go-live date.
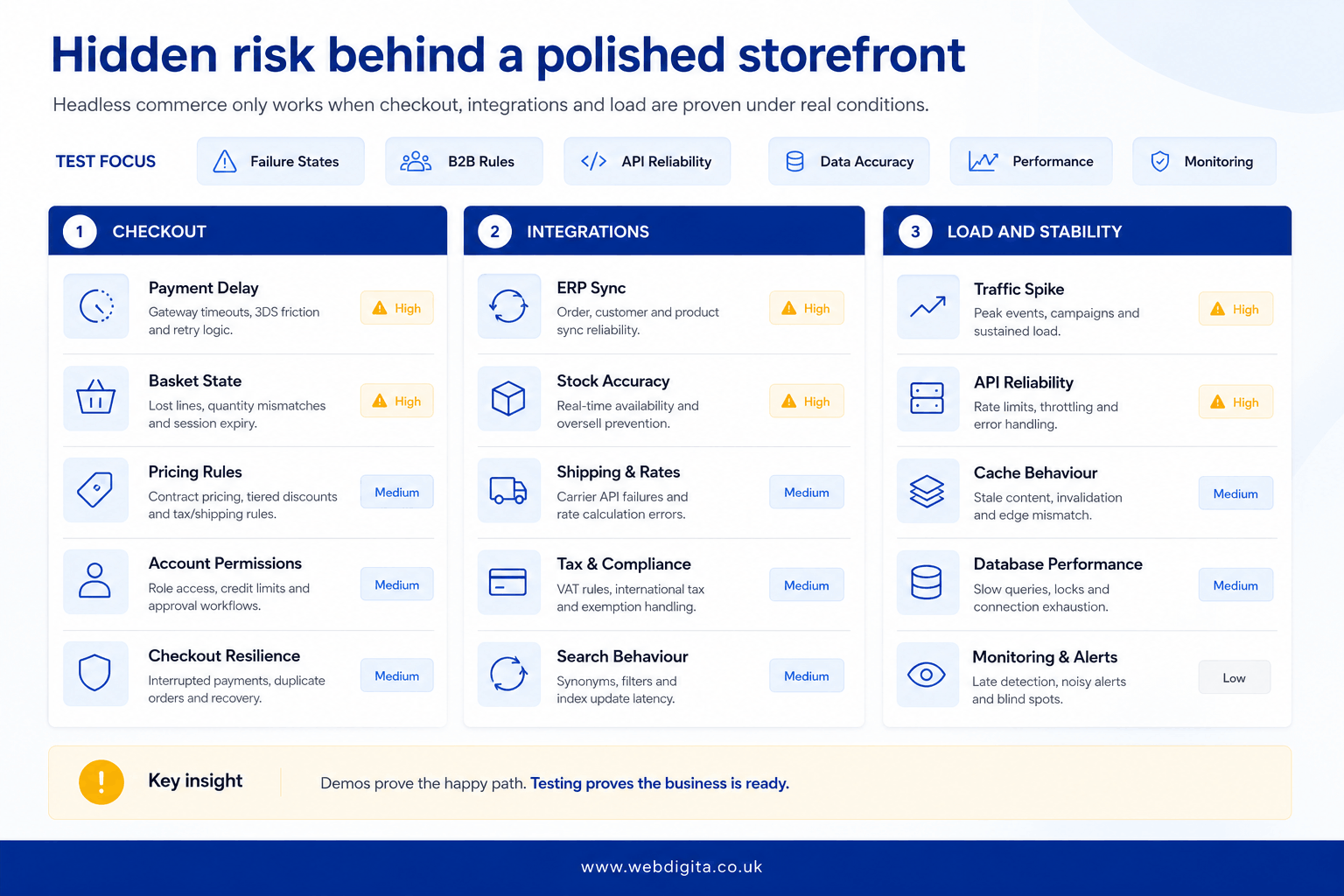
Checkout, integrations, and load are where polished demos fall apart
Pretty storefronts survive demos. Real trading pressure is less polite. Checkout flows, payment handling, ERP sync, search behaviour, stock accuracy, and account permissions are where hidden failure modes show up – and they tend to show up late if testing is left late.
A store can look launch-ready until proper testing starts. Then stock arrives behind from ERP, account pricing applies to the wrong customer group, or a payment delay leaves the basket in limbo. That is not a front-end problem. It is a process problem left too late to fix cheaply.
If you are planning ERP, PIM, shipping, or search integrations, review planning eCommerce integrations before development starts. This is where delivery risk stops being theoretical.
Red-flag test for reviewing an eCommerce agency:
- Ask for failure-state testing, not only successful checkout journeys.
- Check how B2B pricing, permissions, quotes, and account rules are validated end to end.
- Push on load testing, cache behaviour, and stock accuracy under traffic spikes.
- Do not accept “the API handles that” as an integration plan.
- Ask specifically how checkout optimisation is tested across payment providers and device types.
Launch, cutover, and handoff should be planned well before go-live
Launch is not the time to discover who owns content freeze, rollback decisions, monitoring, or defect triage. By then, every unclear assumption carries a cost. A disciplined process plans cutover early, even when the release date has not yet been agreed.
Ask for the sequence, not the promise. You need to know how content freeze works, when routing or sync changes happen, who owns monitoring, what support cover exists in the days after launch, and what defect threshold triggers rollback. Teams that never discuss rollback have usually not thought hard enough about failure.
Handoff matters just as much as go-live. You need documentation, training, a post-launch backlog, and clear ownership of support and optimisation. If your stack includes WordPress and WooCommerce, and you are still weighing delivery approach, speaking with a WordPress development agency may be a useful next step.
A useful next check is the eCommerce development scope checklist to review before signing any quote.
Questions teams ask before starting headless eCommerce development
Common concerns about process, risk, and delivery when scoping a headless build.
1. What should discovery actually produce before headless eCommerce development starts?
Discovery should produce a prioritised scope, dependency map, risk log, and a brief that is ready for decisions. It must expose who owns product data, customer data, pricing rules, promotions, content publishing, and exception handling. Weak discovery collects requirements but misses ownership, constraints, and operational detail. By the end, you should know what conflicts, what will break when APIs hit real trading conditions, and where the real project risk sits.
2. Why does architecture and data design matter more than platform choice in headless eCommerce?
Platform fit is not architecture fit. Headless Shopify, headless WooCommerce, and Magento can all expose APIs, but they stop being interchangeable once B2B pricing, account permissions, catalogue complexity, maintainability, and operational overhead are mapped properly. A platform that looks fine in a demo can become expensive to run once edge cases arrive. Data shape decides more than people think. Variants, bundles, localisation, merchandising rules, subscriptions, trade pricing, and customer-specific catalogues all change how the build should be structured.
3. What are the five stages of a credible headless eCommerce development process?
A credible process moves through risk-led discovery, architecture and data design, phased delivery, hard testing of checkout and integrations, then planned cutover and handoff. Discovery exposes risk and ownership. Architecture settles data assumptions and integration approach. Delivery is phased with visible outputs and client effort. Testing validates checkout, payment flows, ERP sync, stock accuracy, and account permissions under real conditions. Cutover is planned early with rollback logic, monitoring ownership, and support cover mapped before go-live.
4. Where do headless eCommerce projects usually go wrong during delivery?
Most projects go wrong because discovery stayed shallow, integrations were guessed, product data was treated like admin detail, and launch planning started after technical debt was already baked in. The visible brief says new front end, but the real project is an integration and governance problem wearing a design badge. Checkout, payment flows, ERP sync, search behaviour, stock accuracy, and account permissions are where hidden failure modes usually show up. A store can look launch-ready until proper testing starts.
5. What should a headless eCommerce delivery plan include in each phase?
A serious delivery plan should explain outputs, dependencies, and client effort for each phase. Discovery produces scope, risks, dependencies, and success criteria. Solution design produces architecture direction, data assumptions, integration plan, and acceptance logic. UX and build planning produces component plans, content needs, API contracts, and sprint sequencing. Build and QA produces working features, integration validation, defect logs, and acceptance testing. Launch prep produces launch criteria, rollback thinking, monitoring ownership, and handoff. Exact timelines vary, but the logic should always be visible.
6. How should checkout and integrations be tested in headless eCommerce before launch?
Checkout, payment flows, ERP sync, search behaviour, stock accuracy, and account permissions must be tested under real trading pressure, not just successful demo journeys. Ask for failure-state testing. Check how B2B pricing, permissions, quotes, and account rules are validated. Push on load testing, cache behaviour, and stock accuracy under traffic spikes. Do not accept 'the API handles that' as an integration plan. Stock can arrive late from ERP, account pricing can apply to the wrong customer group, or a payment delay can leave the basket in limbo.
7. What should be planned before headless eCommerce launch and cutover?
Launch and cutover should be planned long before go-live. You need to know how content freeze will work, when routing or sync changes happen, who watches monitoring, what support cover exists, and what defect threshold triggers rollback. Teams that never discuss rollback usually have not thought hard enough about failure. Handoff matters just as much. You need documentation, training, a post-launch backlog, and clear ownership for support and optimisation. Launch is not the time to discover who owns content freeze, rollback decisions, monitoring, or defect triage.
8. How do you know if a headless eCommerce supplier has a credible process?
The selection test is simple. Can the supplier show how they move from discovery to cutover without guessing the hard parts, hiding client effort, or hand-waving edge cases? If yes, the process is probably real. If not, you are looking at future rework with better slides. Push on discovery outputs, architecture decisions, data assumptions, integration approach, testing logic, and cutover sequence. If those decisions are still vague, front-end and API work will drift apart. A credible process should feel controlled from the start, not rely on everything somehow coming together near launch.
Conclusion
A headless eCommerce project is only as strong as the process holding it together. The front end might look polished, the stack might sound modern, but if discovery stayed shallow, integrations were guessed, and cutover was planned the week before launch, you are carrying technical debt before the first order arrives.
- Push on discovery early. If a supplier cannot explain who owns product data, pricing rules, content workflows, and exception handling, the brief is not ready for build.
- Settle architecture and data design before development starts. Platform fit is not architecture fit. Variants, bundles, localisation, trade pricing, and customer-specific catalogues all change how the build should be structured.
- Test checkout, integrations, and load under real conditions. Pretty storefronts survive demos, but real trading pressure is less polite. Stock sync, account permissions, payment flows, and search behaviour are where hidden failure modes usually show up.
- Plan cutover and handoff long before go-live. You need to know the sequence, not the promise. Content freeze, rollback decisions, monitoring ownership, and defect triage should be mapped early, even if the release date moves.
The supplier you choose should be able to walk you through discovery, architecture, delivery, testing, and cutover without hand-waving the hard parts. If they cannot, you are looking at future rework with better slides.
Ready to scope a headless ecommerce build that actually accounts for integration, data, and cutover risk?
WEBDIGITA delivers headless ecommerce projects with proper discovery, architecture planning, and phased delivery that keeps checkout, ERP sync, and B2B logic under control. We work with Shopify, WooCommerce, and Magento when the fit is right, and we plan cutover before technical debt gets baked in.
Review eCommerce development servicesOr start with




